
Why Deep Specialty Knowledge Matters in Clinical AI Tools
Why emergency medicine needs EM-specific AI, not generic tools. Learn how specialty training data and domain expertise impact clinical AI performance in EDs.

Most hospitals evaluating clinical AI ask, “Does it work?” A better question is, “Does it work for our specialty?”
Generic AI tools sound appealing. One vendor, one contract, one training program across the entire health system. But there’s a catch. Many clinical AI tools are trained primarily on outpatient and primary care data. When you deploy those same tools in an emergency department, performance often drops.
Emergency medicine has different clinical patterns, workflows, and documentation requirements than primary care. Using clinic trained AI in the ED is like using family practice guidelines in a trauma resuscitation. The approach does not translate.
This is not about vendor preference or feature lists. It is about whether the AI was built to understand how emergency physicians think, work, and document. Domain expertise determines whether AI helps or creates new friction.
This article explains why specialty context matters for AI performance, how emergency medicine differs from primary care in ways that break generic tools, and how to evaluate whether an AI system has real emergency medicine knowledge.
Why “Works for All Specialties” Usually Means “Optimized for None”
Many AI vendors market their tools as universal solutions that work across primary care, specialty care, hospital medicine, and emergency medicine. It sounds appealing. One vendor means simpler contracting. One platform means unified training. One tool for everything.
But AI models learn from training data. And most clinical AI training data comes from the highest-volume setting in healthcare: primary care clinics. Scheduled office visits generate millions of standardized notes. Emergency department visits, while numerous, produce more variable documentation that is harder to standardize for training.
What this means in practice: AI optimized for 15-minute scheduled appointments does not automatically perform well in continuous patient flow. AI trained on single-patient encounters can struggle with simultaneous management. AI that learned documentation patterns from lower-complexity diagnoses can underperform on complex, multi-system complaints.
The performance gap can be meaningful. A generic AI tool may look strong in the clinic setting it was optimized for, then perform noticeably worse in emergency medicine because the clinical patterns, vocabulary, decision-making frameworks, and workflows are different. You can pilot an AI scribe systematically to test this, and the broader research literature supports what emergency physicians experience: AI performance varies across specialties.
So why do vendors claim universal capability? Larger addressable market. Simpler sales narrative. Avoiding the cost of specialty-specific development. But “works everywhere” often means “works acceptably in easy settings, and inconsistently in the hard ones.”
Consider a simple example: chest pain. A primary care model learns a common outpatient pattern: musculoskeletal pain, reflux, or anxiety. Document the history, treat symptomatically, and schedule follow-up. An emergency medicine model learns a different pattern: rule out acute coronary syndrome, pulmonary embolism, and aortic dissection. Order troponin and ECG, apply validated risk tools like the HEART score, and disposition based on risk.
Same chief complaint. Completely different clinical goal. A model trained heavily on the clinic pattern can suggest the wrong pathway when deployed in the ED.
The gap widens when you look at training inputs. AI trained primarily on clinic notes may not reflect emergency medicine clinical reasoning. Tools grounded in emergency medicine sources and patterns, including emergency medicine literature and point-of-care references used by ED clinicians, are more likely to reflect how emergency physicians actually evaluate risk, document uncertainty, and make disposition decisions.
How Emergency Medicine Differs From Primary Care (And Why That Breaks Generic AI)
Emergency medicine differs from primary care across every dimension that matters for AI performance. These are not minor variations. They are the differences that determine whether AI helps or creates friction.
Clinical Decision-Making Patterns
Primary care often works through longitudinal relationships and serial observation. A patient presents with fatigue. The physician orders basic labs, considers common causes, and says, “Let’s try this and follow up in two weeks.” Lower acuity. Lower immediate risk. Pattern recognition built around high-frequency outpatient presentations.
Emergency medicine starts by ruling out the worst-case scenario. A patient presents with fatigue. The physician asks: could this be sepsis, acute coronary syndrome, pulmonary embolism, diabetic emergency, or critical anemia? The work begins with rapid risk stratification, time-sensitive decisions, and undifferentiated presentations that require a broad differential.
Why generic AI fails: It often does not recognize when emergency decision tools apply. It may default to outpatient-style follow-up language when the ED is making a disposition decision now. It can miss the “sick versus not sick” framing that drives prioritization, testing, and documentation in emergency care. And it struggles to capture the reasoning under uncertainty that ED documentation needs to make explicit.
Documentation Requirements
The documentation gap between primary care and emergency medicine is substantial.
Primary Care vs. Emergency Medicine Documentation:
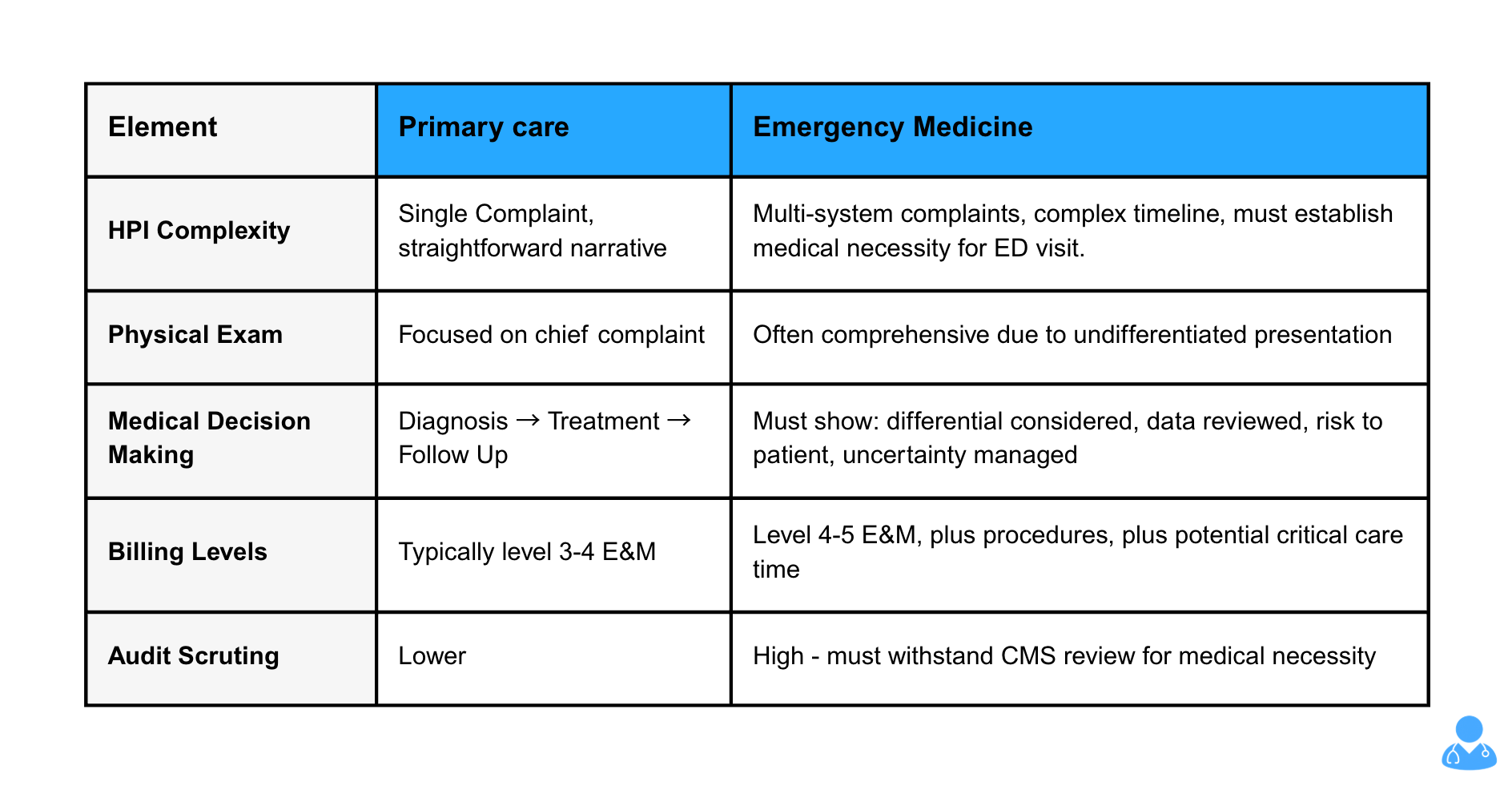
Why generic AI fails: It generates clinic-style notes that under-support emergency medicine billing levels. It misses elements needed to establish medical necessity. It doesn't prompt for critical care time documentation. It creates compliance risk by producing documentation that won't withstand audit scrutiny.
Workflow Patterns
Primary care runs on scheduled appointments with mostly sequential encounters. You finish one visit before starting the next. There is often buffer time built into the day. Most visits center on one primary complaint. Interruptions happen, but they are not the default.
Emergency medicine runs on continuous flow and parallel work. Physicians manage multiple active patients at once, while new arrivals keep coming. Interruptions are routine: traumas, codes, consult calls, and urgent reassessments. Context switching every few minutes is normal, not a breakdown in process. Multi-tasking is the workflow.
Why generic AI fails: it struggles to maintain context across rapid patient switching. It often assumes a clean “start encounter, document, close encounter” sequence that does not exist in the ED. When the underlying workflow assumptions are wrong, accuracy drops and review burden increases.
Clinical Vocabulary and Concepts
Emergency medicine relies on vocabulary and concepts that rarely appear in primary care documentation.
Examples include “FAST exam positive for free fluid,” “GCS 14, E4V4M6,” “sedated for procedural sedation with propofol,” “Wells score low, no imaging indicated,” and “discussed case with accepting intensivist for ICU admission.”
This is not jargon for its own sake. It is precise communication that carries clinical meaning. A FAST result can change management immediately. A GCS score and its components matter for trending and disposition decisions. Wells score logic drives imaging decisions and documentation of medical decision-making.
Generic AI trained mostly on clinic notes often has limited exposure to this language and the context behind it. The result is documentation that can miss critical details, misinterpret intent, or fail to prompt the elements emergency physicians expect to capture.
Research consistently shows that domain-specific training data improves performance in clinical AI. Tools trained on emergency medicine sources such as emergency medicine literature, WikEM, and specialty-focused clinical modules are more likely to recognize this vocabulary, apply it appropriately, and produce notes that feel native to emergency department practice.
How to Test Whether AI Actually Knows Emergency Medicine
Do not take vendor claims at face value. Test for specialty knowledge using these five scenarios.
Test 1: Clinical Decision Rule Recognition
Present a chest pain case during your demo or trial. Does the AI recognize that a HEART score calculation would help risk stratify the patient. For a patient with possible pulmonary embolism, does it identify when Wells criteria or the PERC rule apply. Can it appropriately incorporate Ottawa ankle or knee rules for trauma cases.
Generic AI: Suggests a generic workup or misses these decision tools entirely.
EM-specific AI: Prompts for the appropriate decision tool based on the presentation.
Test 2: Multi-Patient Context Management
Start documenting patient A with abdominal pain. Mid-documentation, switch to patient B with chest pain. Then return to patient A. Does the AI maintain separate, accurate context for each patient without mixing details or forcing you to close and restart encounters.
Generic AI: Loses context, mixes patient details, or requires finishing one encounter before starting another.
EM-specific AI: Tracks multiple active patients and maintains distinct context for each.
Test 3: Medical Necessity Documentation
Document a moderate-complexity case. Does the AI help establish why this patient required emergency department evaluation rather than urgent care or outpatient follow-up. Does it prompt for elements that support medical necessity and the level of service billed.
Generic AI: Produces a clinic-style note that often falls short for emergency department billing.
EM-specific AI: Captures patient-specific medical necessity and supports the appropriate billing level.
Test 4: Procedure and Critical Care Capture
Document a case involving a procedure such as a laceration repair or joint reduction. Does the AI recognize that a procedure occurred and prompt for indication, technique, and complications. For a patient who meets critical care criteria, does it recognize this and prompt for time documentation and medical necessity.
Generic AI: Misses procedures or captures them without billing-critical elements.
EM-specific AI: Flags procedures as they occur and prompts for the elements needed for compliant billing.
Test 5: Differential Diagnosis Breadth
Present an undifferentiated complaint such as chest pain or abdominal pain. Does the AI support an emergency medicine differential that prioritizes life-threatening conditions and reflects risk stratification.
Generic AI: Skews toward common outpatient diagnoses such as GERD or IBS.
EM-specific AI: Includes must-not-miss diagnoses and reflects an ED-first approach.
How to conduct these tests
During vendor demos or pilot trials, request these scenarios explicitly. Avoid demos built around simple, low-acuity cases. Test the complex workflows and edge cases that define real emergency medicine practice. The difference between generic and specialty-specific capability becomes obvious quickly.
The Real Costs of Using Generic AI in Emergency Departments
Choosing a generic AI tool instead of one built for emergency medicine is not just a feature tradeoff. It creates measurable downstream costs that can outweigh any savings on licensing.

Cost 1: Revenue Leakage
Generic AI often misses billing-critical documentation that emergency physicians rely on for accurate reimbursement. Procedures such as laceration repairs, joint reductions, and incision and drainage may not be captured completely. Critical care time may go undocumented or lack the detail needed to support billing. Medical decision-making may read as thinner than the care delivered, which increases downcoding risk.
Even a $30 to $40 gap per visit adds up quickly at emergency department scale. For example, a 50,000-visit department missing $35 per patient loses $1.75 million annually.
Cost 2: Compliance Risk
Documentation that does not meet CMS expectations for medical necessity and billed level increases audit exposure. Generic AI often produces notes that feel closer to outpatient documentation patterns. In the ED, that can mean less clarity on risk, uncertainty, data reviewed, and decision-making complexity. When auditors do not see the support they expect for high-acuity billing, downcoding and denials follow.
Repayments, penalties, and audit response costs can eclipse any savings from a cheaper tool.
Cost 3: Physician Abandonment
If the tool does not match ED workflow, physicians stop using it. Systems that struggle with interruptions, multi-patient management, or ED-style reasoning create friction. After a short trial period, usage drops, and the department is left with an implementation that technically exists but does not change daily work.
The hidden cost is not just wasted licensing. It is lost training time and reduced confidence in future AI initiatives.
Cost 4: Downstream Documentation Work
When AI misses key elements, it does not eliminate the documentation burden. It shifts it. Coders and HIM teams spend more time issuing queries, chasing missing details, and clarifying procedures or critical care criteria after the fact.
Instead of reducing administrative load, the tool redistributes it to people who were not in the room and cannot efficiently reconstruct what happened.
Cost 5: Opportunity Cost
Time spent trying to make a generic tool fit emergency medicine is time not spent evaluating and deploying a solution designed for the ED. That delays ROI, prolongs charting burden, and adds avoidable friction for clinicians.
The False Economy
Generic AI may cost 20 to 30 percent less. But if it leads to lower revenue capture, higher audit exposure, and inconsistent physician adoption, the “savings” disappear. In emergency medicine, the lower-priced option that does not fit the workflow often costs more than the tool built for the job.
What Real Emergency Medicine Expertise Looks Like in AI
After understanding why specialty matters and how to test for it, here is what genuine emergency medicine expertise looks like in clinical AI.
Built by Emergency Medicine Physicians
Domain expertise starts with who designed the tool. Teams that build for every specialty often end up with a generic solution. Emergency medicine physicians who understand the workflow, clinical reasoning, and documentation requirements can help shape tools that work in real emergency departments.
The difference shows up in practical design decisions. Clinicians who have worked high volume shifts know what breaks first. They know which decision tools are used most often, where documentation typically degrades, and which billing elements get missed. That perspective helps the product match real ED conditions instead of an idealized workflow.
Trained on Emergency Medicine Data
AI learns from examples. Training data determines which patterns the system recognizes and how it performs in practice.
Generic AI is often trained heavily on outpatient documentation because it is abundant and more standardized. As a result, it learns clinic language, clinic patterns, and clinic workflows.
Emergency medicine specific AI should be trained on emergency medicine data. Research demonstrates that physician involvement in AI development and specialty-specific training data produce better clinical outcomes. That includes emergency department documentation and emergency medicine resources such as PubMed literature, WikEM, and StatPearls modules. This foundation determines whether the tool understands how emergency physicians evaluate risk, apply decision rules, and document medical necessity under time pressure.
Integrates EM Clinical Decision Support
Specialty specific AI does not just document what physicians say. It supports emergency medicine decision making in real time.
It recognizes when a chest pain workup would benefit from HEART score documentation and prompts for the needed elements. It can surface when PERC or Wells criteria may apply in a possible PE case. It can support Ottawa rules for ankle and knee injuries. It can also flag when critical care documentation may be needed based on the clinical scenario and the work performed.
Handles EM Workflow Reality
Multi patient management is not a nice to have feature. It is the operating condition of emergency medicine. Emergency medicine specific AI should be designed to track simultaneous patients, handle interruptions, and maintain clean context across rapid switching.
Optimizes for EM Billing Complexity
Emergency medicine billing differs from clinic billing in ways that matter for documentation. Specialty specific AI should support medical necessity documentation, capture procedures with required elements, recognize critical care scenarios, and help produce notes that support the appropriate billing level and can hold up to review.
Examples in Practice
Case studies of emergency medicine specific AI can help validate these capabilities in real departments, including multi patient workflow support, guideline aligned decision support, and documentation built for emergency medicine billing complexity. In documented case studies, outcomes have included substantial recovered revenue per physician through better capture of care that was already delivered but not consistently documented.
How to Make the Case Internally for Specialty Specific Tools
When you need to justify investing in emergency medicine specific AI rather than accepting good enough generic tools, here is how to frame it for different stakeholders.
For Finance Leadership
Generic AI costs X but captures Y percent less revenue due to missed procedures, incomplete critical care documentation, and weaker support for appropriate billing levels. Emergency medicine specific AI costs about 20 percent more but can capture meaningfully more revenue by improving documentation quality for ED billing requirements. Net return on investment should be evaluated on total financial impact, not license price alone.
Lead with numbers. Show the revenue gap. Calculate the net impact using your department volume and payer mix. Finance leaders understand that paying more can be the cheaper decision when it improves revenue capture and reduces rework.
For Clinical Leadership
Physician adoption depends on workflow fit. Generic AI often forces emergency physicians to adapt to the tool. Emergency medicine specific AI is designed around how ED clinicians actually practice. Higher adoption drives the return on investment. Lower adoption from a poor fit means the organization pays for a tool that does not get used consistently.
Clinical leaders care about physician experience and operational efficiency. They also know that a tool that looks strong in a demo can fail if it creates friction during high volume shifts.
For Compliance and Risk Leadership
Emergency medicine billing is complex and frequently reviewed by payers. Documentation that does not meet CMS criteria for medical necessity and medical decision making increases audit exposure. Emergency medicine specific AI that is designed to support ED documentation requirements can reduce that risk by producing clearer, more defensible notes.
Risk and compliance leaders respond to defensibility. Frame specialty specific AI as risk reduction alongside efficiency and revenue.
The Question to Ask Vendors
When evaluating AI tools, ask for concrete emergency department demonstrations. For example, show how the tool handles three simultaneous patients at different stages of care. Show how it recognizes when a chest pain patient warrants HEART score documentation. Show an example note that supports appropriate high complexity billing, including critical care time when applicable.
If a vendor cannot demonstrate emergency medicine capability in these scenarios, you are likely looking at a generic tool that has not been built for ED workflow reality.
Conclusion
Deep specialty knowledge is not a marketing claim or a nice to have feature. It is the difference between clinical AI that helps emergency physicians and AI that creates new problems while claiming to solve old ones.
Generic tools trained mostly on primary care data often underperform in emergency medicine. The clinical patterns, workflows, documentation requirements, and billing complexity are fundamentally different. These are not small differences that a generic model reliably adapts to in real ED conditions. They determine whether the tool actually fits.
The evaluation framework above gives you objective criteria to test for true emergency medicine expertise. Decision rule recognition, multi patient context management, medical necessity support, procedure and critical care capture, and an ED appropriate differential. These are measurable capabilities that separate tools built for emergency medicine from tools repackaged for it.
Emergency departments deserve tools built for ED realities, not one size fits all platforms optimized for clinic settings and marketed as universal. When the stakes include revenue integrity, compliance posture, and physician satisfaction, specialty expertise matters.
To see the difference in practice, review case studies with measured ED outcomes, or request a demonstration that focuses on the emergency medicine scenarios that matter most to your team.
About the Author
Nathan Murray, M.D. Emergency Medicine - Founder of DocAssistant
Dr. Nathan Murray is an Emergency Medicine trained physician and the founder of DocAssistant. With years of frontline clinical experience, Dr. Murray is passionate about using AI to streamline medical documentation and enhance clinical decision making.


