
How Contextual Understanding Sets Next-Gen AI Scribes Apart
Two AI scribes can listen to the same emergency department encounter and produce notes that look nearly identical - but bill at completely different levels. The difference isn't the audio quality or the vocabulary. It's whether the tool understands what it heard.

Two AI scribes listen to the same emergency department encounter. A physician walks into the room, introduces themselves, takes a history, performs an exam, reviews prior records and imaging, discusses risk with the patient, and formulates a plan. Both tools record everything that was said. Both generate a note.
The notes look similar on the surface. Similar structure, similar length, similar clinical vocabulary. But one of them supports a Level 5 billing level. The other supports a Level 4. One of them accurately reflects the MDM complexity of what just happened in that room. The other transcribes what was said without understanding what it meant.
That gap - between recording and understanding - is the most important distinction in the AI scribe market right now, and it's the one most vendor comparisons obscure rather than clarify.
What Surface Transcription Actually Is
The first generation of AI scribes was, in most meaningful respects, a speech-to-text engine with a medical vocabulary layer on top. The tool listened, it converted audio to text, and it organized that text into a note structure. For physicians who had been dictating into a recorder and waiting for a transcriptionist, this felt transformative. Notes got done faster. Post-shift charting time dropped. The burden was lighter.
What surface transcription does not do - and was never designed to do - is understand what it's hearing. It captures what was said, not what it meant clinically. It records that the physician mentioned reviewing lab results, but it doesn't understand whether that review constitutes low, moderate, or high complexity data analysis under MDM guidelines. It transcribes that the physician discussed prescription drug management as a risk factor, but it doesn't recognize that this element supports a specific MDM risk tier. It hears the words. It doesn't understand the clinical reasoning those words represent.
In low-complexity clinical environments - a straightforward follow-up visit, a minor acute complaint, a routine prescription renewal - this limitation is manageable. The encounter is simple, the documentation requirements are straightforward, and a well-organized transcription is often sufficient.
Emergency medicine is not a low-complexity clinical environment. It is the environment where the gap between transcription and understanding shows up most consequentially - in documentation quality, in billing accuracy, and in audit defensibility.
Why the ED Exposes the Limits of Surface Transcription
Emergency medicine creates a documentation challenge that is categorically different from other care settings, and surface transcription tools are not architecturally equipped to handle it.
An ED encounter is rarely a linear conversation. It's interrupted, non-sequential, multi-party, and compressed under time pressure. A physician may document findings out of order, circle back to clinical reasoning they mentioned earlier, receive a lab result mid-encounter that changes their differential, or conduct a brief family history conversation while simultaneously reviewing imaging. The encounter is layered, not linear - and the clinical significance of what's being said depends entirely on context that a transcription engine doesn't carry forward.
Under the 2023 CMS E/M guidelines, every ED note is coded based on MDM complexity across three specific domains: the number and complexity of problems addressed, the amount and complexity of data reviewed and analyzed, and the risk of complications or morbidity or mortality of patient management. Each of those domains requires the documentation to reflect not just what happened, but the clinical reasoning behind it - why the physician ordered certain tests, what diagnoses were considered and ruled out, what risk factors influenced the management decision.
A surface transcription tool captures the outputs of that reasoning if the physician verbalizes them explicitly. What it cannot do is recognize when an element of MDM complexity was present in the clinical interaction but not stated aloud - and prompt the physician to document it before the chart is finalized. That gap is where revenue leaks. A 2024 scoping review published in Cureus examining AI's impact on clinical documentation accuracy across hospital wards, emergency departments, and outpatient clinics found that while AI tools demonstrated clear efficiency gains, documentation accuracy - particularly in complex, unstructured clinical environments - remained the primary variable separating effective implementations from ineffective ones. Surface transcription tools performed well on efficiency metrics and less consistently on accuracy in high-complexity settings.
What Surface Transcription Misses in a Real ED Encounter
Three specific failure modes appear consistently in ED environments when surface transcription tools are applied to high-complexity documentation requirements.
✦ MDM context collapse
The physician reviews three sets of external records, considers two competing diagnoses, and selects a management plan that accounts for a significant comorbidity. The note reflects that labs were reviewed and a plan was made. The clinical reasoning that connects those elements - the complexity of data analysis, the risk stratification, the differential reasoning - doesn't make it into the documentation because the tool captured the outputs without understanding the process.
✦ Speaker attribution errors and multi-voice confusion
A 2025 PMC review examining the risks of AI scribes in clinical practice found that current AI systems struggle to consistently distinguish between multiple speakers, potentially attributing patient statements to clinicians or vice versa. In an ED encounter involving the physician, a nurse, and a family member - all providing clinically relevant information - a tool that can't reliably attribute speech to the correct speaker is generating a note with embedded accuracy risk that the physician may not catch during a rushed review.
✦ Billing-relevant element omission
The physician prescribes a controlled substance, documents the prescription, but doesn't explicitly state that prescription drug management was a risk factor in the MDM assessment. The tool records the prescription. It doesn't recognize that this element - if documented with the appropriate MDM framing - supports a higher billing level. The chart bills lower than it should, not because the care was less complex, but because the documentation didn't connect the clinical action to its billing significance.
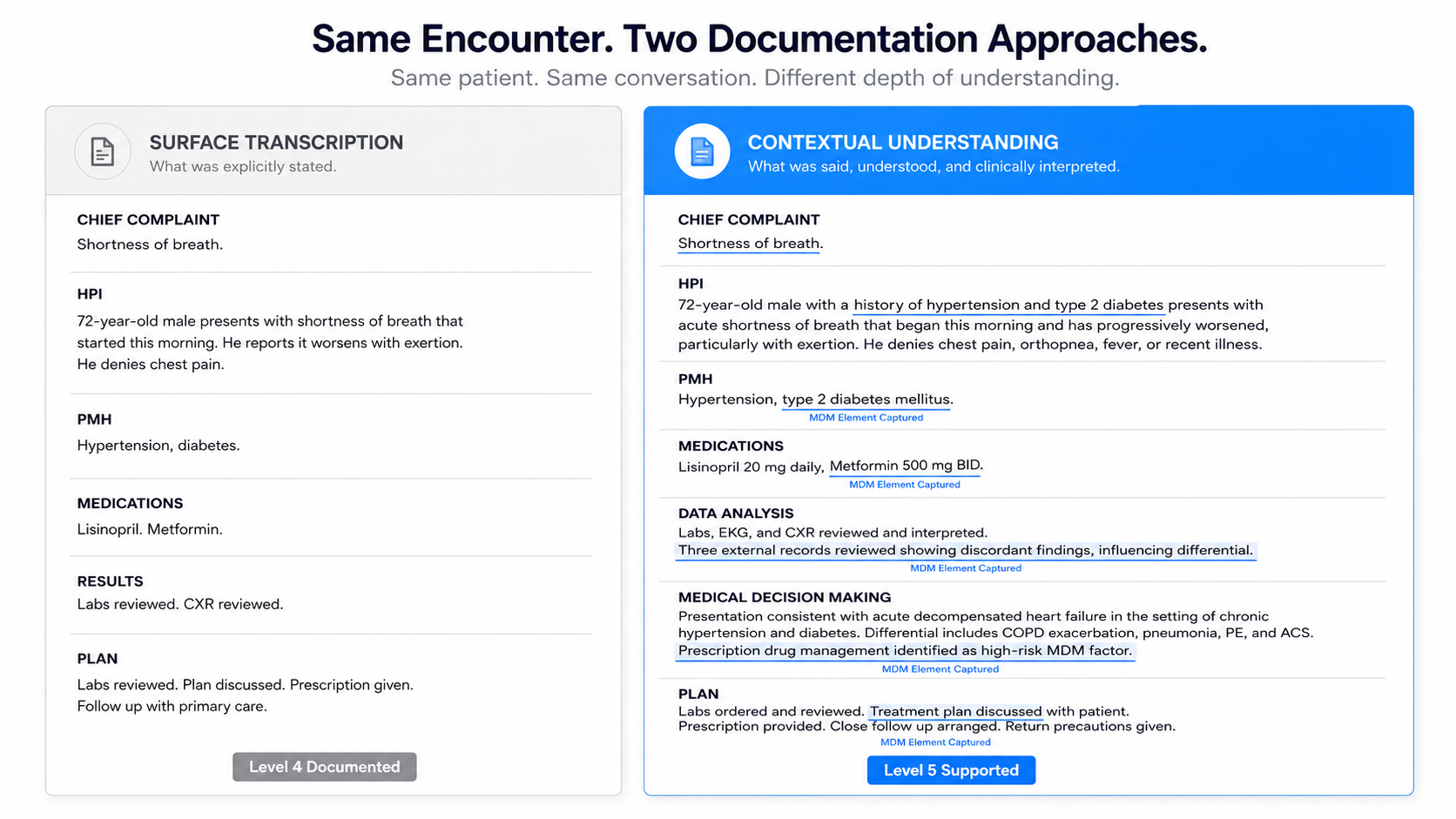
[GRAPHIC PLACEHOLDER #1] Suggested: Side-by-side panel showing the same fictional ED encounter documented two ways. Left panel labeled "Surface Transcription Output" — clean note, complete sentences, but MDM elements present only where explicitly stated. Right panel labeled "Contextually Understood Output" — same encounter, but MDM complexity elements flagged, risk tier identified, data analysis documented with appropriate complexity language. DocAssistant blue on the right panel, neutral grey on the left. Should feel like a documentation quality comparison, not a marketing graphic.
What Contextual Understanding Actually Means - Technically
Clinical contextual understanding is not a single feature. It's a design architecture that shapes how an AI scribe processes clinical language at every stage of the documentation workflow.
At the most basic level, it means the tool was trained on clinical literature specific enough to recognize the semantic difference between a physician saying "I reviewed the outside records" and a physician saying "I reviewed three sets of outside records from different providers, which showed discordant findings that influenced my differential." Both sentences describe record review. Only one of them reflects the data complexity that MDM coding requires.
A 2024 meta-analysis published in Academic Emergency Medicine reviewing NLP applications in emergency medicine found that NLP performance in emergency settings was generally favorable but highly variable depending on the specificity of the training corpus and the complexity of the clinical task being performed. Tools trained on broad medical language outperformed general-purpose language models on ED-specific documentation tasks, but specialty-specific training - tools built around emergency medicine vocabulary, workflows, and MDM coding requirements - outperformed both. The study identified disease recognition and clinical reasoning extraction as the tasks where training specificity mattered most - exactly the tasks that determine documentation quality under MDM guidelines.
This is why the training corpus of an AI scribe isn't a technical footnote. It's the architectural decision that determines whether the tool understands clinical context or simply processes clinical language. A tool trained on 9,000 peer-reviewed medical articles, specifically curated for acute care presentations and reviewed by specialty-trained physicians, is operating with a fundamentally different contextual foundation than a general-purpose large language model fine-tuned on medical text.
The practical expression of contextual understanding in a documentation workflow looks like this: the physician conducts the encounter. The tool doesn't just transcribe - it recognizes which clinical elements carry MDM significance, structures them into the appropriate documentation framework, and flags when the documented complexity supports a billing level that differs from what was initially assigned. The physician reviews a note that has already done the analytical work of connecting clinical actions to their documentation implications.
How to Evaluate Whether an AI Scribe Actually Has Contextual Understanding
Most vendor demos are designed to show transcription quality - how cleanly the tool converts a sample encounter into a note. That's the wrong test for contextual understanding. Here is a four-question framework for evaluating whether a tool actually understands clinical context or is performing sophisticated transcription.
1. Ask the vendor what the tool does when an MDM element is present in the encounter but not explicitly stated
Surface transcription tools don't do anything - they document what was said. Contextually intelligent tools recognize when a clinical action implies an MDM element and either document it appropriately or prompt the physician to confirm it before sign-off. If the vendor can't give you a specific, demonstrable answer to this question, you're looking at a transcription tool.
2. Ask to see a note from a high-complexity ED encounter involving multiple data sources, competing diagnoses, and prescription drug management
Review the note for MDM specificity - does it reflect the complexity of data analysis in language that supports the appropriate billing tier? Does it document risk stratification in a way that connects clinical actions to their MDM significance? A well-transcribed note and a contextually intelligent note look very different on this test.
3. Ask what the tool's training data looks like and how it was curated
General-purpose LLMs and specialty-trained models produce materially different documentation quality on complex ED encounters. The answer "trained on medical literature" is not sufficient. The relevant question is: trained on what medical literature, curated by whom, and updated how frequently? Tools trained on static datasets from general medical sources are not the same as tools trained on continuously updated peer-reviewed acute care literature reviewed by practicing emergency physicians.
4. Ask how the tool handles multi-speaker encounters and non-linear conversation
This is where speaker attribution accuracy matters. Ask specifically: what happens when a family member interjects with clinically relevant history? What happens when the physician circles back to a finding mentioned earlier in the encounter? A contextually intelligent tool maintains encounter context across those non-linear elements. A transcription tool logs them sequentially and hopes the physician catches what didn't get connected.
How DocAssistant AI Was Built Around Contextual Understanding
Most AI scribe tools were built to solve the transcription problem - to get notes done faster by removing the manual documentation step from the physician's workflow. That's a real problem, and they solve it reasonably well. What they weren't built to solve is the clinical reasoning problem: ensuring that the documentation reflects not just what happened in the encounter, but the complexity and significance of what happened, in language that supports accurate billing and defensible clinical records.
DocAssistant AI was designed from the ground up by practicing emergency physicians who understood both problems simultaneously. The result is an architecture that addresses contextual understanding at every layer where surface transcription falls short.
The training foundation is 9,000 peer-reviewed medical articles curated through a direct partnership with StatPearls - the largest continuously updated point-of-care medical resource in medicine, reviewed by more than 8,000 specialty-trained authors and editors across all major medical specialties. That training corpus isn't a general medical dataset. It's a specialty-specific clinical knowledge base that gives the platform the contextual foundation to recognize MDM significance in clinical language - not just transcribe it.
The MDM billing analyzer is the direct application of that contextual understanding to the billing problem. Every chart is reviewed against 2023 CMS E/M guidelines in real time. The tool doesn't wait for the physician to explicitly state MDM complexity - it analyzes the documented clinical content against the criteria and flags when the documentation supports a different billing level than was initially assigned. That's not transcription. That's clinical reasoning applied to documentation.
The platform is EHR-agnostic and trained specifically on emergency medicine encounters - which means it handles the non-linear, multi-party, high-complexity conversations that define an ED shift better than general-purpose tools that were adapted from outpatient clinical environments.
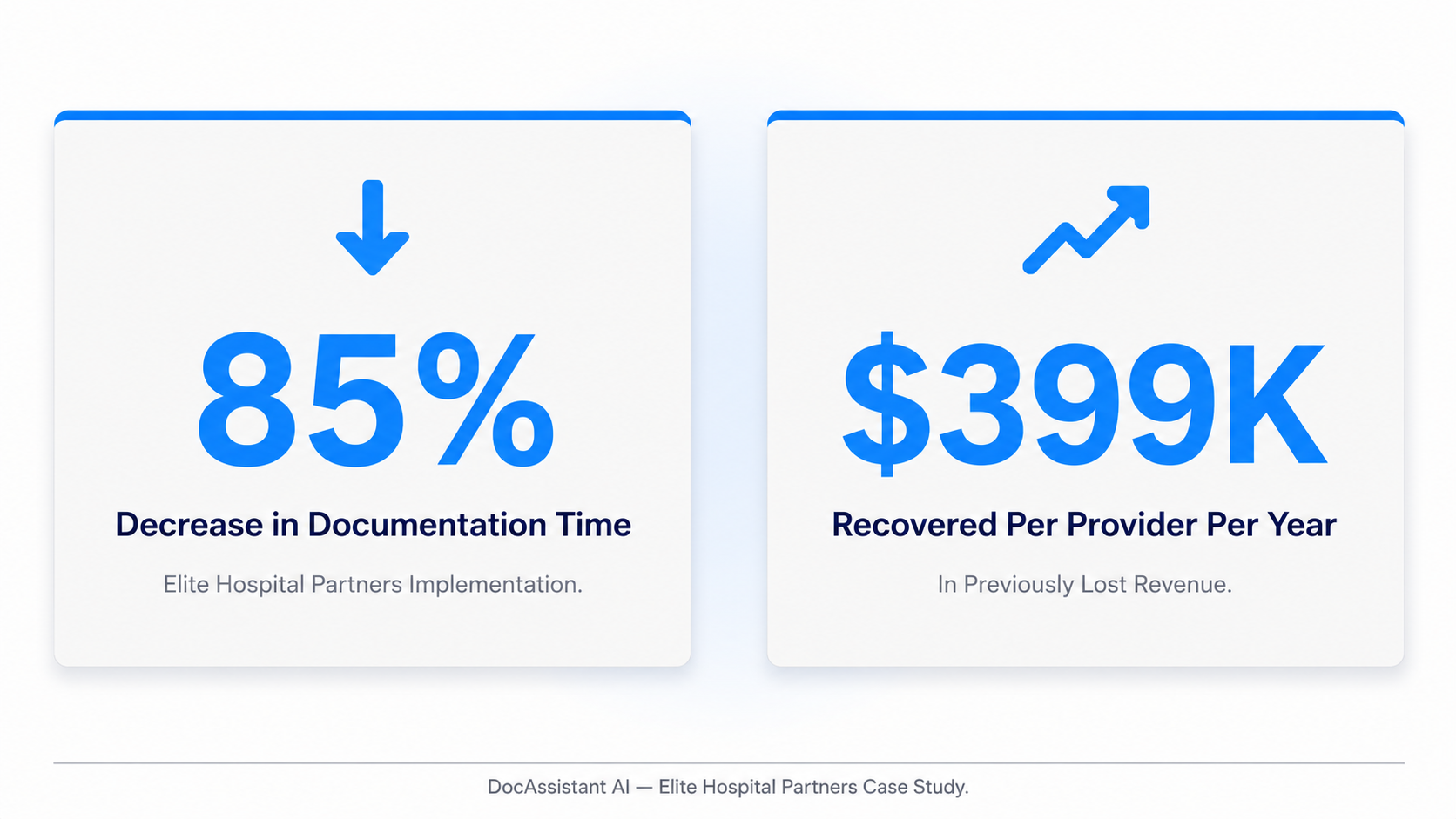
The outcome at Elite Hospital Partners reflects all of this directly:
85% reduction in charting time per provider, a 12% increase in Level 5 chart capture, and $399,000 recovered per provider per year in previously lost revenue.
Those aren't transcription outcomes. They're contextual understanding outcomes - the direct financial expression of documentation that captures clinical complexity accurately, consistently, and in real time.
For physicians who want to see what that looks like in practice - what a contextually intelligent note looks like compared to a transcription-first note on the same encounter type - the case study data behind those outcomes is worth reviewing in detail.
Why This Distinction Matters Beyond Documentation
The contextual understanding gap between surface transcription tools and purpose-built clinical platforms isn't just a documentation quality issue. It's a clinical safety issue, a revenue issue, and a compliance issue simultaneously - and understanding that connection is what makes this a strategic technology decision rather than a procurement one.
On clinical safety: a note that doesn't reflect the full complexity of clinical reasoning is a note that creates continuity risk. The physician who picks up the patient on the next shift is working from incomplete documentation of what was considered, what was ruled out, and why. In emergency medicine, where patients return, deteriorate, and require disposition decisions based on prior visit records, that incompleteness has downstream clinical consequences.
On revenue: as established in the before/after data from Elite Hospital Partners and across the broader research, the revenue gap between surface transcription and contextual understanding is not marginal. It's the difference between $3,000 per physician per year in incremental RVU improvement from general ambient tools and $399,000 per provider per year in recovered revenue from purpose-built MDM analysis.
On compliance: payers are increasingly scrutinizing coding intensity following AI scribe adoption. The organizations that will navigate that scrutiny successfully are the ones whose documentation accurately reflects clinical complexity - not because they coded higher, but because their tool understood what happened in the encounter well enough to document it completely. That's the compliance defense that holds up. Transcription-first documentation that happens to have supported higher billing levels through completeness alone is a weaker position.
The distinction between surface transcription and contextual understanding is, ultimately, the distinction between a tool that records medicine and a tool that understands it. In emergency medicine, that difference is measurable - in the note, in the bill, and in the chart that the next physician reads when your patient comes back.
If your organization is currently evaluating AI scribes and wants to see what contextual understanding looks like in a live ED documentation workflow, DocAssistant AI offers structured pilot sessions designed around your specific encounter types, EHR environment, and MDM complexity profile. For teams also working through how this connects to documentation governance and audit readiness, the compliance framework for AI-generated notes is worth reviewing alongside the documentation quality question.
About DocAssistant
DocAssistant is an AI-powered medical scribe, clinical decision support platform, and point-of-care billing tool built for acute care. Founded by practicing emergency physicians and headquartered in San Diego, California, DocAssistant reduces documentation time by over 80%, optimizes billing in real time against 2023 CMS E&M guidelines, and delivers evidence-based clinical recommendations backed by 9,000+ peer-reviewed articles. HIPAA-compliant and trusted by emergency and acute care physicians across the United States.
docassistant.ai | hello@docassistant.ai | (619)-344-0849
Nathan Murray
DocAssistant
+1 619-344-0849
Visit us on social media:
